Στόχος της τρέχουσας ενότητας είναι να παρουσιαστούν οι δυνατότητες που προσφέρει η Python για την οπτικοποίηση δεδομένων σε διαγράμματα. Για την δημιουργία των διαγραμμάτων θα χρησιμοποιηθεί η βιβλιοθήκη seaborn.
Ειδική ενότητα για εκτέλεση στο Google Colab¶
# έλεγχος αν το notebook τρέχει στο google colab
try:
import google.colab
IN_COLAB = True
except:
IN_COLAB = False# αν το notebook τρέχει στο colab, mount το Google Drive και αλλαγή στο directory που έχει γίνει clone το github repository.
# εγκατάσταση απαραίτητων βιβλιοθηκών
if IN_COLAB:
from google.colab import drive
drive.mount('/content/drive')
%cd /content/drive/MyDrive/Colab\ Notebooks/programming/notebooks
!pip install pandas seabornimport pandas as pd # η βιβλιοθήκη pandas για την διαχείριση πινάκων
import seaborn as sns # η βιβλιοθήκη seaborn για δημιουργία διαγραμμάτων
import matplotlib.pyplot as plt # η βιβλιοθήκη matplotlib για δημιουργία διαγραμμάτων, πιο σύνθετη
sns.set() # ορισμός προκαθορισμένων ρυθμίσεων για την βιβλιοθήκη matplotlib και seaborn (themes, fonds, scaling, color palette)Διαγράμματα με γραμμές (line plots), ραβδογράμματα (bar plots), γραφήματα πίτας (pie charts)¶
Στο παρακάτω παράδειγμα θα παρουσιαστεί σε μορφή διαγράμματος με γραμμές (line chart) η διαχρονική εξέλιξη του πληθυσμού για την περίοδο 2010-2020 για μια σειρά από χώρες.
Για την επίδειξη της δημιουργίας ενός διαγράμματος σε γραμμές θα χρησιμοποιηθούν διαδέσιμα δεδομένα από την πλατφόρμα kaggle.
Πληθυσμός ανά χώρα για την περίοδο 2010-2020¶
Πηγή: Kaggle, Countries population. 2010 - 2020 data. ISO codes, https://
Το εν λόγω dataset περιλαμβάνει ανα έτος τον πληθυσμό ανά χώρα για την περίοδο 2010-2020.
Αρχικά διαβάζουμε το αρχείο csv και προσαρτούμε τα περιεχόμενά του σε μια νέα μεταβλητή με το όνομα mydata.
mydata = pd.read_csv("../docs/plots_data/countries_general_info_historical.24-10-2021.csv") # Σύντομη προεπισκόπηση:
mydata.head()Τα δεδομένα είναι διαθέσιμα σε μορφή wide. Αυτό σημαίνει ότι ο πληθυσμός κάθε έτους δίδεται σε διαφορετική στήλη. Για την ευκολότερη αξιοποίηση των δεδομένων πρέπει να μετατρέψουμε τα δεδομένα σε μορφή long.
(Διαβάστε για την διαφορά μεταξύ wide και long data format εδώ.)
Μετατροπή και προεπισκόπηση:
mydata_long = pd.wide_to_long(mydata, stubnames=["Population"], i="Name", j="year", sep=", ")
mydata_longΜετά την μετατροπή οι στήλες με τον πληθυσμό ανά έτος συγχωνεύτηκαν σε μία στήλη. Η στήλη Population περιλαμβάνει τον πληθυσμό από όλα τα έτη. Ωστόσο η διάκριση ανά έτος γίνεται με βάση το index year που περιλαμβάνει το έτος αλλά και το όνομα της χώρας. Στην πράξη το index του πίνακα είναι MultiIndex αφού κάθε εγγραφή Index αποτελείται από μία πλειάδα με την Χώρα και το έτος. Αυτό μπορούμε να το επιβεβαιώσουμε με την παρακάτω εντολή.
mydata_long.indexMultiIndex([( 'Canada', 2010),
( 'Japan', 2010),
( 'Norway', 2010),
( 'Ireland', 2010),
( 'Hungary', 2010),
( 'Spain', 2010),
( 'United States of America', 2010),
( 'Belgium', 2010),
( 'Luxembourg', 2010),
( 'Finland', 2010),
...
( 'Rwanda', 2019),
( 'Sao Tome and Principe', 2019),
( 'Senegal', 2019),
( 'Seychelles', 2019),
( 'Sierra Leone', 2019),
( 'Somalia', 2019),
( 'Sudan', 2019),
( 'Eswatini', 2019),
('Kingdom of the Netherlands', 2019),
( 'Danish Realm', 2019)],
names=['Name', 'year'], length=1920)Σαν πρώτο παράδειγμα θα χρησιμοποιήσουμε μόνο τα δεδομένα της Ελλάδας, φιλτράροντας με βάση το πεδίο Iso3166P1Alpha2Code.
mydata_long=mydata_long[mydata_long.Iso3166P1Alpha2Code.isin(["GR"])]
mydata_long.head(5)
Διάγραμμα γραμμής¶
Στην συνέχεια φτιάχνουμε ένα διάγραμμα με γραμμές με βάση τα δεδομένα της Ελλάδας.
# create plot
myplot = sns.lineplot(x = "year", y = "Population", data=mydata_long, hue="Name",marker="o", palette=["green"] )
myplot.set(title='Πληθυσμιακή μεταβολή 2010-2019') # Ορισμός τίτλου
myplot.ticklabel_format(style='plain', axis='y') # ορισμός y axis labels σε plain format αντι scientific
plt.show()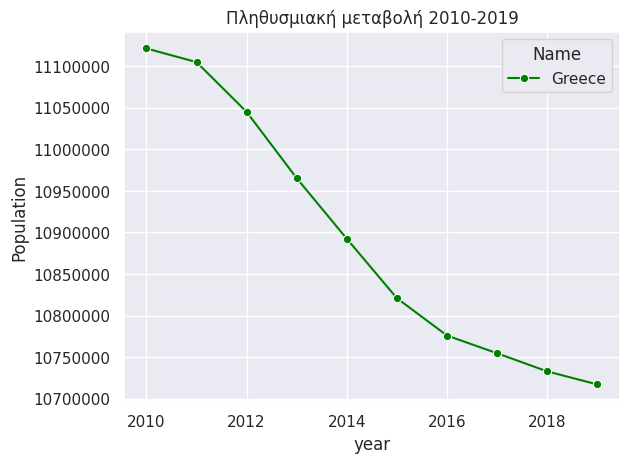
Ραβδόγραμμα¶
Μπορούμε να αποδώσουμε το παραπάνω διάγραμμα και σαν ραβδόγραμμα όπου το μέγεθος του πληθυσμού κάθε έτους είναι μια στήλη το ύψος της οποίας εξαρτάται από το μέγεθος του πληθυσμού.
# bar plot
myplot = sns.barplot(x = "year", y = "Population", data = mydata_long)
myplot.ticklabel_format(style='plain', axis='y')
plt.ylim(10700000, 11150000)
plt.show()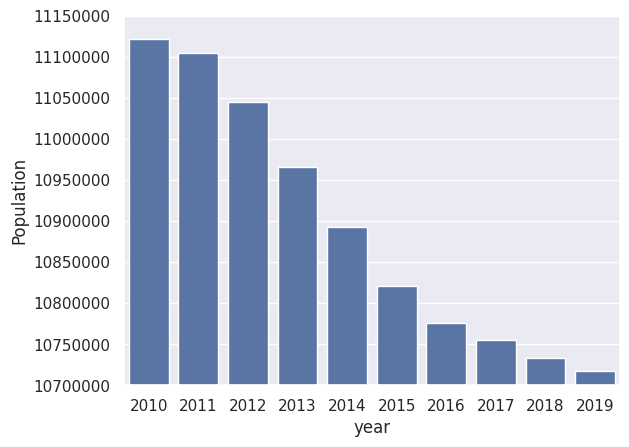
Είναι δυνατή η δημιουργία διαγράμματος γραμμών με πολλαπλές γραμμές όπου κάθε γραμμή αντιστοιχεί στην διαχρονική μεταβολή του πληθυσμού διαφορετικής χώρας. Φιλτράρουμε τον αρχικό πίνακα (dataframe) και κρατάμε όσες χώρες είχαν πληθυσμό το 2019 > 10500000 και < 11500000. Αντίστοιχα μετατρέπουμε το φορμάτ του πίνακα από wide σε long.
mydata_2 =mydata[(mydata['Population, 2019'] > 10500000) & (mydata['Population, 2019'] < 11500000)]
mydata_long2 = pd.wide_to_long(mydata_2, stubnames=["Population"], i="Name", j="year", sep=", ")fig, myplot = plt.subplots(figsize = (11,7))
myplot = sns.lineplot(x = "year", y = "Population", data=mydata_long2, hue="Name",marker="o" )
myplot.axes.set_title("Πληθυσμιακή μεταβολή",fontsize=20)
myplot.set_xticks(mydata_long2.index.get_level_values(level="year").unique().tolist())
myplot.set_xlabel('Έτος', fontsize = 18)
myplot.set_ylabel ('Πληθυσμός', fontsize = 18)
myplot.ticklabel_format(style='plain', axis='y') # disable scientific format
sns.move_legend(myplot, "upper left", bbox_to_anchor=(1, 1)) # μετακίνηση του Legend εκτός γραφήματος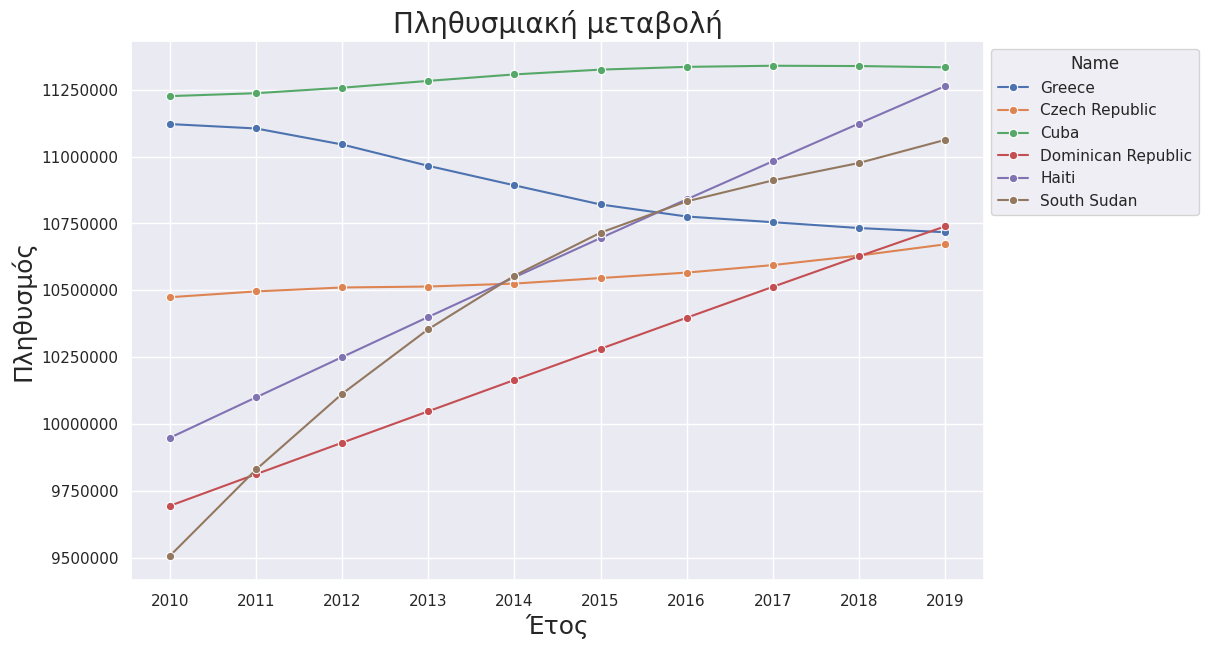
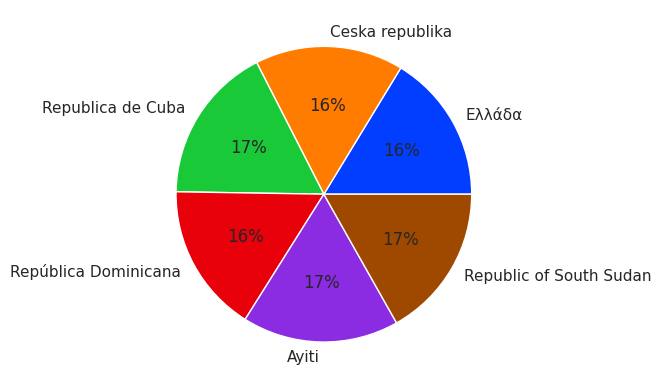
Γράφημα πίτας¶
Αν θέλουμε να εκφράσουμε γραφικά την αναλογία του πληθυσμού του 2019 κάθε χώρας σε σχέση με το σύνολο των χωρών τότε μπορούμε να χρησιμοποιήσουμε ένα διάγραμμα “πίτας” (pie chart).
# pie chart
df = mydata_long2[mydata_long2.index.isin([2019], level='year')]
dfpalette_color = sns.color_palette('bright')
pie = plt.pie(df['Population'], labels = df['NativeName'], colors = palette_color, autopct='%.0f%%')
plt.show()
Ιστόγραμμα συχνοτήτων, θηκόγραμμα¶
Στην ενότητα αυτή θα χρησιμοποιηθούν δεδομένα πληθυσμού ανά έτος και περιφέρεια NUTS2 για την περίοδο 2010 - 2021.
(Πηγή: Εurostat, Population and demography, Demography, population stock and balance, Population on 1 January by NUTS 2 region, https://
Ανάγνωση του σχετικού αρχείο δεδομένων:
nuts2 = pd.read_csv("../docs/plots_data/eurostat/tgs00096_page_linear.csv") #
Φιλτράρουμε μόνο τον πληθυσμό για το 2021
nuts2_2021 = nuts2[nuts2['TIME_PERIOD'] == 2021] Ιστόγραμμα συχνοτήτων¶
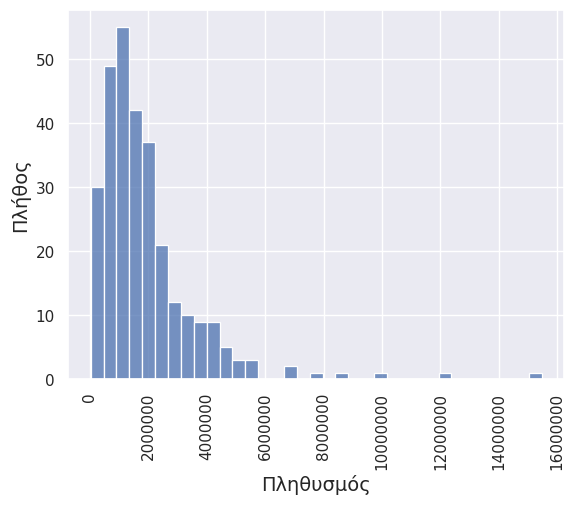
Το ιστόγραμμα συχνοτήτων περιγράφει την κατανομή μίας μεταβλητής. Μετράει τον αριθμό των παρατηρήσεων που περιέχονται ανά κλάση τιμών.
myplot = sns.histplot(data=nuts2_2021, x="OBS_VALUE", bins=35)
myplot.ticklabel_format(style='plain', axis='x')
myplot.set_xlabel('Πληθυσμός', fontsize = 14)
myplot.set_ylabel ('Πλήθος', fontsize = 14)
plt.xticks(rotation=90)
sns.set(rc={"figure.figsize": (12, 12)})
plt.show()
Θηκόγραμμα (box-plot)¶
Το θηκόγραμμα περιγράφει την κατανομή μιας μεταβλητής μέσω της οπτικοποίησης του διαμέσου, του ενδοτεταρτημοριακού εύρους, του upper και lower whisker.
Δημιουργία θηκογράμματος
sns.boxplot(data=nuts2_2021, x=nuts2["OBS_VALUE"])
plt.show()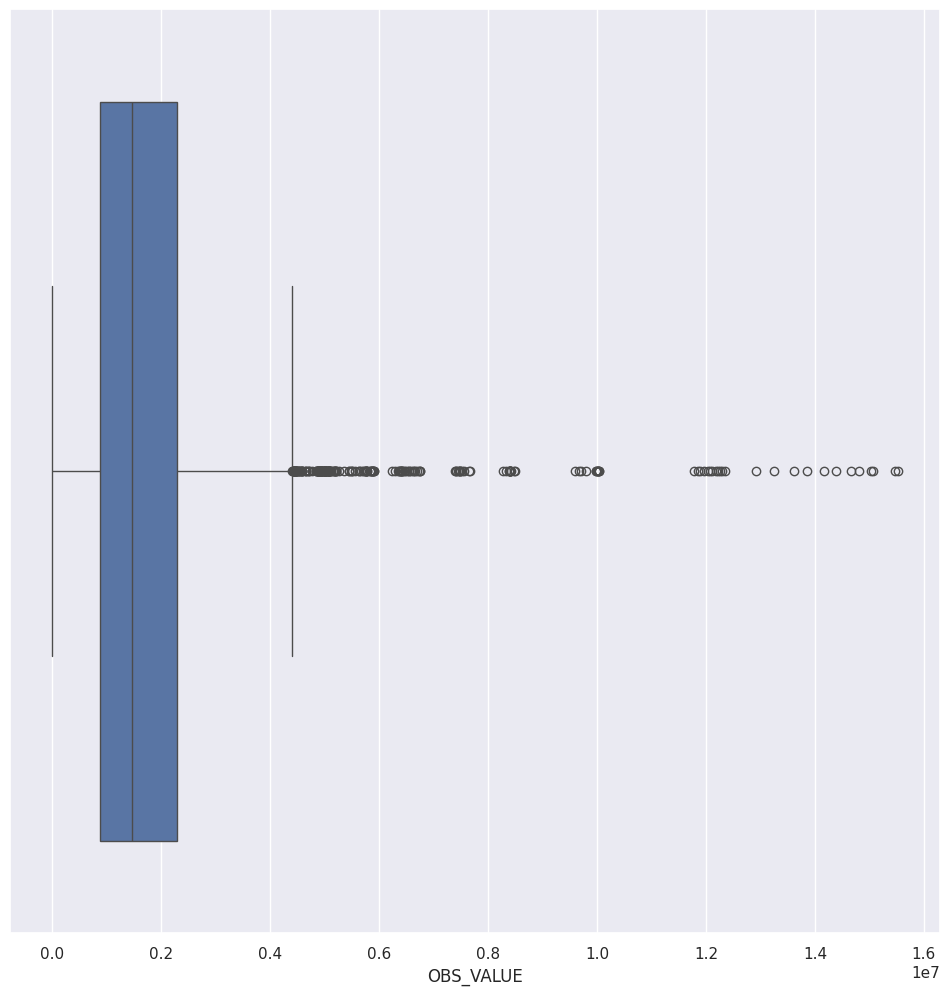
Για λόγους σύγκρισης μπορούμε να δημιουργήσουμε πολλαπλά θηκογράμματα με κριτήριο κατηγοριοποίησης των δεδομένων μια κατηγορική μεταβλητή.
Στο συγκεκριμένο παράδειγμα χρησιμοποιούμε σαν κριτηρίο κατηγοριοποίησης την μεταβλητή TIME_PERIOD αφού πρώτα την μετατρέψουμε σε κατηγορική. Το αποτέλεσμα του παρακάτω κώδικα θα είναι να πάρουμε ένα θηκόγραμμα για τα δεδομένα κάθε έτους.
nuts2 = nuts2[nuts2['TIME_PERIOD'].isin([2010,2018,2019,2020])]
nuts2['TIME_PERIOD'] = nuts2.TIME_PERIOD.astype('category') # SOS
sns.boxplot(data=nuts2, x="OBS_VALUE", y="TIME_PERIOD")
plt.show()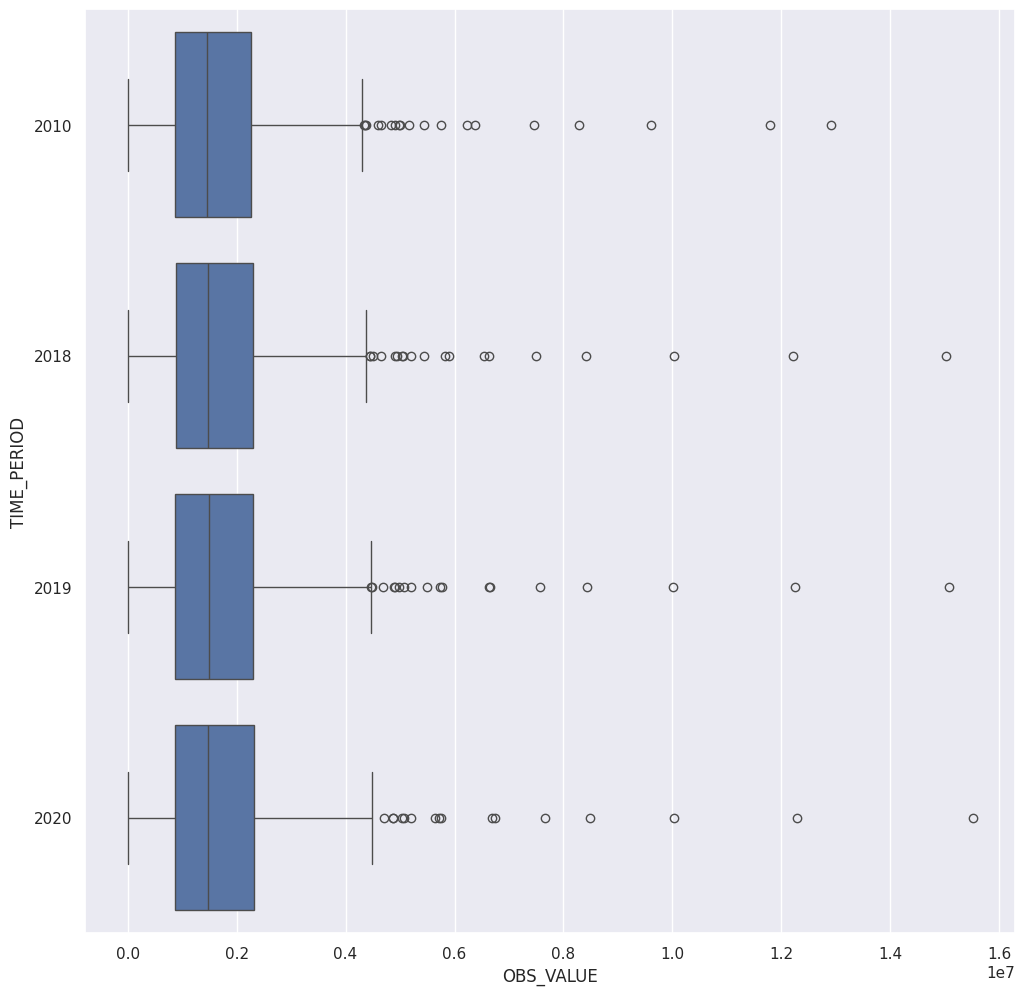
Επιπλέον είναι εφικτό να δημιουργήσουμε ξεχωριστά θηκογράμματα ανά έτος μέσω της συνάρτησης FacetGrid:
g = sns.FacetGrid(nuts2, col="TIME_PERIOD", height=3, col_wrap=4)
g.map(sns.boxplot, "OBS_VALUE", order=None)
g.set_xlabels('Πληθυσμός', fontsize = 12)
for ax in g.axes.flatten():
ax.ticklabel_format(style='plain', axis='x')
plt.show()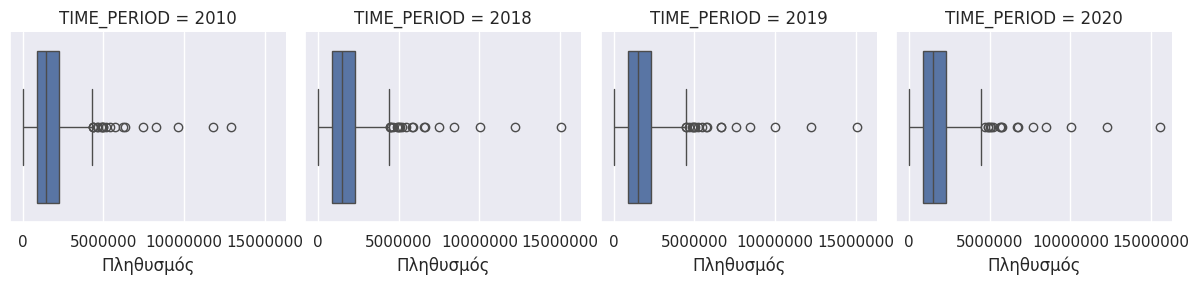
Αντίστοιχα μπορούμε να κάνουμε το ίδιο με πολλαπλά ιστογράμματα. Το σημαντικό είναι να αλλάξουμε την τιμή της παραμέτρου που δέχεται η συνάρτηση g.map από sns.boxplot σε sns.histplot.
g = sns.FacetGrid(nuts2, col="TIME_PERIOD", height=3, col_wrap=4)
g.map(sns.histplot, "OBS_VALUE")
g.set_xlabels('Πληθυσμός', fontsize = 12)
for ax in g.axes.flatten():
ax.ticklabel_format(style='plain', axis='x')
plt.show()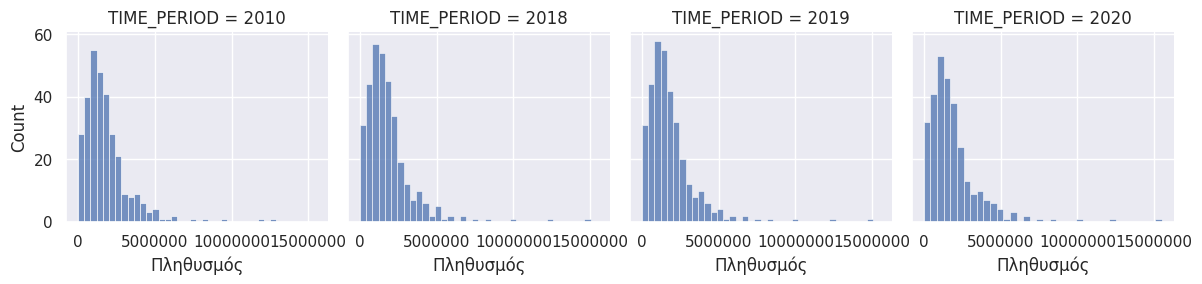
Διάγραμμα διασποράς (scatterplot), φυσαλίδων (bubble chart), μήτρας συσχετίσεων (correlation matrix), συντελεστής συσχέτισης, γραμμή παλινδρόμησης¶
# Deaths by age, sex and NUTS 2 region
#https://ec.europa.eu/eurostat/databrowser/view/demo_r_magec/default/table?lang=enΣτην τρέχουσα ενότητα παρουσιάζεται η δημιουργία ενός διαγράμματος διασποράς με την χρήση οικονομικών δεδομένων από την Ελληνική στατιστική υπηρεσία (ΕΛ.ΣΤΑΤ.). Θα χρησιμοποιηθεί ο Οικονομικά ενεργός και μη ενεργός πληθυσμός, οι απασχολούμενοι κατά τομέα οικονομικής δραστηριότητας, και οι άνεργοι για τους δήμους της Ελλάδας.
(Πήγη: ΕΛΣΤΑΤ, Οικονομικά χαρακτηριστικά 2011, 23. Οικονομικά ενεργός και μη ενεργός πληθυσμός, απασχολούμενοι κατά τομέα οικονομικής δραστηριότητας, άνεργοι. Δήμοι, https://
Ανάγνωση του σχετικού αρχείου δεδομένων:
econ_data = pd.read_csv("../docs/plots_data/A1602_SAM04_TB_DC_00_2011_B23_F_GR.csv",sep=';')
econ_data.head()Το αρχείο περιλαμβάνει δεδομένα για διαφορετικά διοικητικά επίπεδα. Κρατάμε μόνο τους δήμους (έχουν Επίπεδο διοικητικής διαίρεσης με τιμή 3) και αφαιρούμε το Άγιο Όρος.
econ_data = econ_data[econ_data['Επίπεδο διοικητικής διαίρεσης']=='3']
econ_data = econ_data[econ_data['Περιγραφή']!='ΔΗΜΟΙ ΑΡΙΣΤΟΤΕΛΗ ΚΑΙ ΑΓΙΟ ΟΡΟΣ (ΑΥΤΟΔΙΟΙΚΗΤΟ)']Υπολογίζουμε το % απασχολουμένων ανά τομέα οικονομικής δραστηριότητας επί του οικονομικά ενεργού πληθυσμού, και το ποσοστό ανεργίας (ως νέα στήλη unempl_pct):
econ_data[['A_pct', 'B_pct', 'C_pct']] = (econ_data[['Πρωτογενής Τομέας', 'Δευτερογενής Τομέας', 'Τριτογενής Τομέας']]
.apply(lambda x: 100*x/x.sum(), axis=1))
econ_data['unempl_pct'] = 100*econ_data['Ανεργοι']/econ_data['Σύνολο οικονομικών ενεργών']
Μετονομασία στήλης ‘Γεωγραφικός κωδικός’ σε ‘DHMOSID’. Θα χρειαστεί στην συνέχεια σαν κλειδί για να συνδέσουμε πίνακες. Επιπλέον θα ορίσουμε τον τύπο δεδομένων της στήλης σε συμβολοσειρά.
econ_data = econ_data.rename(columns={'Γεωγραφικός κωδικός': 'DHMOSID'})
econ_data['DHMOSID'] = econ_data['DHMOSID'].astype(str) # SOS Είναι εφικτή η αποθήκευση ενός pandas dataframe σαν αρχείο (πχ CSV):
econ_data.to_csv('../docs/plots_data/output/econ_data.csv', index=False)Διάγραμμα διασποράς¶
sns.scatterplot(data=econ_data, x="A_pct", y="C_pct")
plt.show()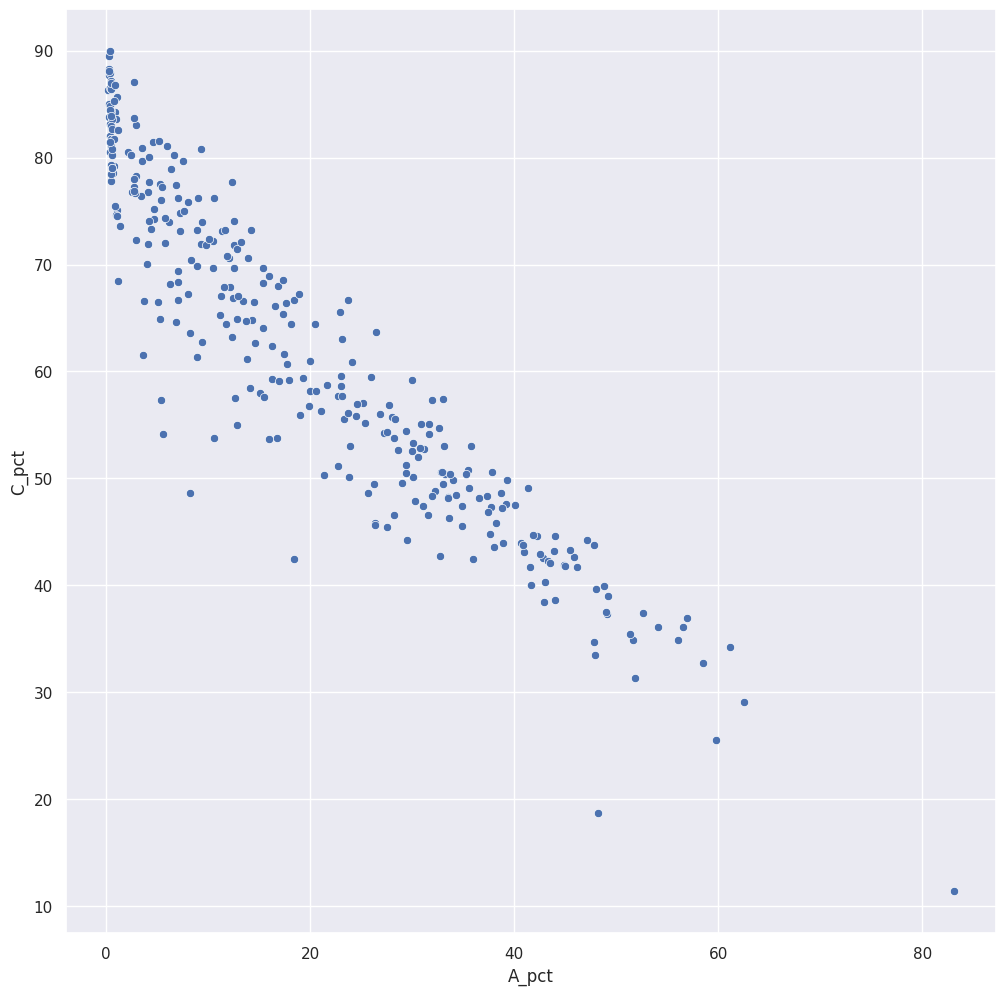
Bubble Chart¶
Μέσω της συνάρτησης scatterplot() της βιβλιοθήκης seaborn είναι δυνατή η δημιουργία bubble charts. Στην συνάρτηση αυτή υπάρχει η παράμετρος size η οποία καθορίζει το μέγεθος του κύκλου με βάση μια στήλη με αριθμητικά δεδομένα.
sns.scatterplot(data=econ_data, x="A_pct", y="C_pct", size="Σύνολο", legend=False, sizes=(20, 2000))
plt.show()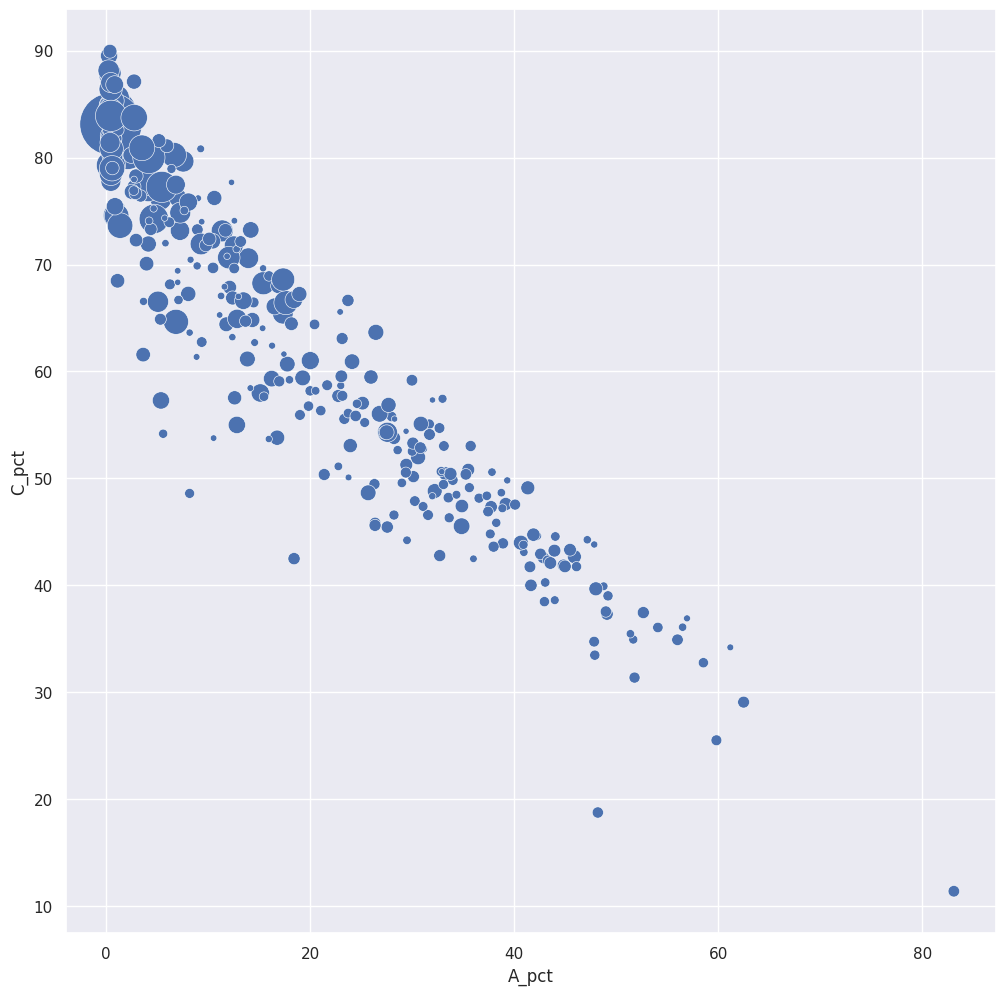
Ο συντελεστής συσχέτισης, γραμμή παλινδρόμησης, γράφημα μήτρας συσχετίσεων¶
Για την επίδειξη του κώδικα της τρέχουσας ενότητας θα αξιοποιηθούν δεδομένα απασχόλησης κατά επίπεδο εκπαίδευσης από την ΕΛ.ΣΤΑΤ. Στόχος είναι να υπολογίσουμε τον συντελεστής συσχέτισης ανάμεσα στο ποσοστό πτυχιούχων πρωτοβάθμιας εκπαίδευσης και το ποσοστό απασχολουμένων στον τριτογενή τομέα.
Πηγή: ΕΛΣΤΑΤ, Οικονομικά χαρακτηριστικά 2011, Β.10 Απασχολούμενοι κατά επίπεδο εκπαίδευσης. Δήμοι, https://
Ως συνήθως ξεκινάμε με την ανάγνωση του σχετικού αρχείου.
edu_data = pd.read_csv("../docs/plots_data/A1602_SAM04_TB_DC_00_2011_B10_F_GR.csv",sep=';')
edu_data = edu_data[edu_data['Γεωγραφικό επίπεδο']==5]
edu_data['Γεωγραφικό επίπεδο'] = edu_data['Γεωγραφικό επίπεδο'].astype('int') # SOS μετατροπή στήλης σε ακέραιο
edu_data = edu_data.rename(columns={'Γεωγραφικός κωδικός': 'DHMOSID'})
edu_data['DHMOSID'] = edu_data['DHMOSID'].astype(str) # μετατροπή στήλης σε συμβολοσειρά
edu_data['DHMOSID'] = edu_data['DHMOSID'].str[1:] # αφαίρεση πρώτου χαρακτήρα για να ταιριάζει με το DHMOSID του econ_dataΥπολογισμός του ποσοστού πτυχιούχων ανά βαθμίδα εκπαίδευσης
edu_data[['clevel_pct', 'metadeyt_pct', 'blevel_pct', 'alevel_pct']] = edu_data[['Κάτοχοι διδακτορικού ή μεταπτυχιακού τίτλου / Πτυχιούχοι Παν/μίου - Πολυτεχνείου, ΑΤΕΙ, ΑΣΠΑΙΤΕ ανώτερων επαγγελματικών και ισότιμων σχολών',
'Πτυχιούχοι μεταδευτεροβάθμιας εκπαίδευσης (ΙΕΚ, Κολλέγια κλπ.) / Απόφοιτοι Λυκείου (Γενικού, Εκκλησιαστικού, Επαγγελματικού κλπ.)',
'Απόφοιτοι τριτάξιου Γυμνασίου και πτυχιούχοι Επαγγελματικών Σχολών',
'Απόφοιτοι Δημοτικού / Άλλη περίπτωση(1)']].apply(lambda x: 100*x/x.sum(), axis=1)
Σύνδεση πινάκων¶
df_cd = pd.merge(econ_data, edu_data, how='inner', on = 'DHMOSID')df_cd.columns
Index(['Επίπεδο διοικητικής διαίρεσης', 'DHMOSID', 'Περιγραφή', 'Σύνολο_x',
'Σύνολο οικονομικών ενεργών', 'Σύνολο απασχολούμενων',
'Πρωτογενής Τομέας', 'Δευτερογενής Τομέας', 'Τριτογενής Τομέας',
'Ανεργοι', 'Οικονομικά μη ενεργοί', 'A_pct', 'B_pct', 'C_pct',
'unempl_pct', 'Γεωγραφικό επίπεδο', 'Περιγραφή τόπου μόνιμης διαμονής ',
'Σύνολο_y',
'Κάτοχοι διδακτορικού ή μεταπτυχιακού τίτλου / Πτυχιούχοι Παν/μίου - Πολυτεχνείου, ΑΤΕΙ, ΑΣΠΑΙΤΕ ανώτερων επαγγελματικών και ισότιμων σχολών',
'Πτυχιούχοι μεταδευτεροβάθμιας εκπαίδευσης (ΙΕΚ, Κολλέγια κλπ.) / Απόφοιτοι Λυκείου (Γενικού, Εκκλησιαστικού, Επαγγελματικού κλπ.)',
'Απόφοιτοι τριτάξιου Γυμνασίου και πτυχιούχοι Επαγγελματικών Σχολών',
'Απόφοιτοι Δημοτικού / Άλλη περίπτωση(1)', 'clevel_pct', 'metadeyt_pct',
'blevel_pct', 'alevel_pct'],
dtype='object')Ο συντελεστής συσχέτισης Pearson¶
Ο συντελεστής συσχέτισης περιγράφει την στατιστική εξάρτηση μεταξύ δύο μεταβλητών.
corr = df_cd['alevel_pct'].corr(df_cd['C_pct'], method='pearson') # οι δυνατές τιμές για την παράμετρο method είναι 'pearson', 'kendall' ή 'spearman'
corr-0.8677231838338612Γραμμή παλινδρόμησης¶
myplot = sns.regplot(data=df_cd, #regplot: Plot data and a linear regression model fit.
x="alevel_pct",
y="C_pct",
scatter_kws={"color": "black"}, line_kws={"color": "red"})
myplot.set_xlabel('% απασχολούμενων στον Α-γενή τομέα', fontsize = 14)
myplot.set_ylabel ('% απασχολούμενων απόφοιτοι γ\' βάθμιας εκπαίδευσης', fontsize = 14)
sns.set(rc={"figure.figsize": (10, 8)})
plt.show()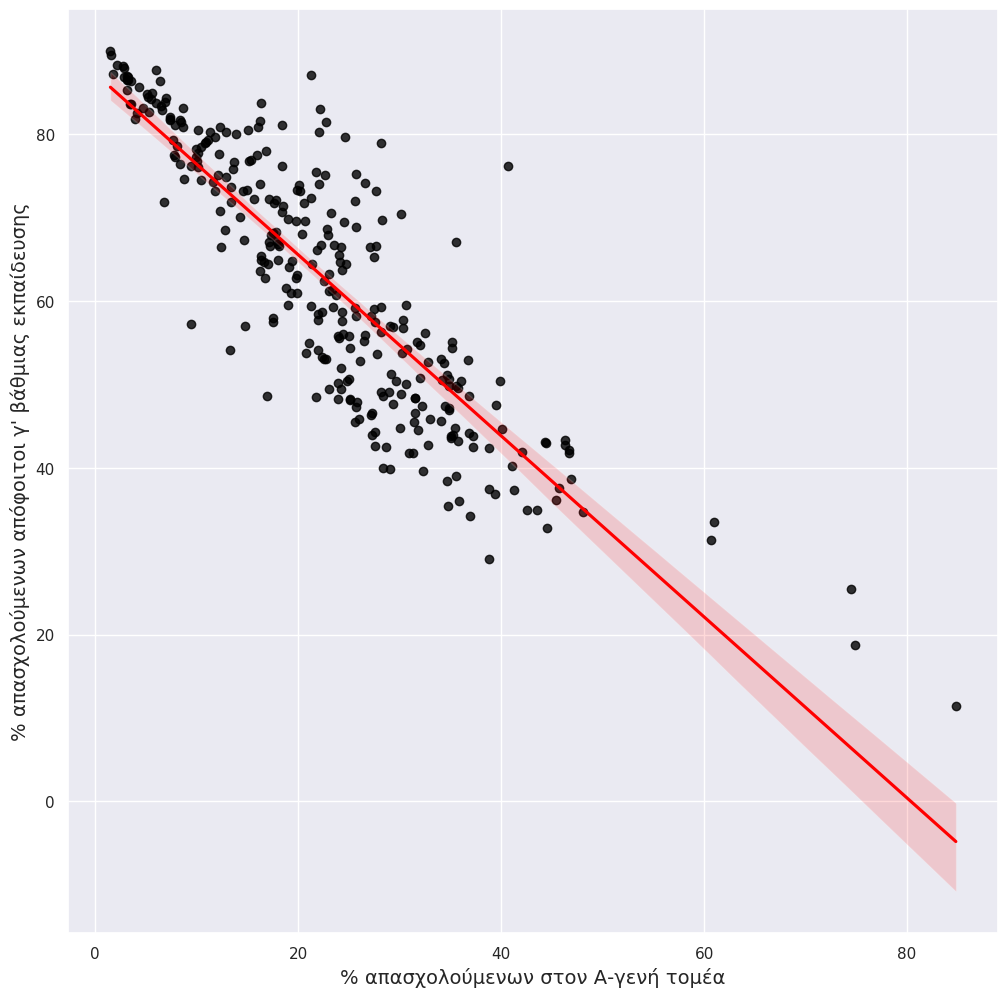
Είναι δυνατή η αποθήκευση ενός διαγράμματος σε μορφή εικόνας:
fig = myplot.get_figure()
fig.savefig("../docs/plots_data/output/out_linear.png") Γράφημα μήτρας συσχετίσεων (Correlation matrix)¶
Για το συγκεκριμένο παράδειγμα θα χρησιμοποιηθεί ένα διαδεδομένο αρχείο δεδομένων, το αρχείο Iris. Το αρχείο Iris χρησιμοποιείται σαν δοκιμαστικό αρχείο για μεθόδους στατιστικής ανάλυσης, μηχανικής εκμάθηση και οπτικοποίησης και περιλαμβάνει 50 εγγραφές για κάθε ένα από τα είδη λουλουδιών Iris setosa, Iris virginica, και Iris versicolor για το μήκος και το πλάτος για τα σέπαλα και τα πέταλα τους. Περισσότερες λεπτομέρειες για το συγκεκριμένο αρχείο δεδομένων μπορείτε να βρείτε στην Wikipedia.
Ως συνήθως αρχικά γίνεται η ανάγνωση του σχετικού αρχείου:
iris = pd.read_csv('../docs/plots_data/Iris.csv')Η μήτρα συσχετίσεων καλέιται μέσω της μεθόδου corr() ενός pandas dataframe και υπολογίζει την συσχέτιση μεταξύ των στηλών του αντίστοιχου dataframe. To αποτέλεσμα είναι ένα dataframe.
Στο τρέχον παράδειγμα η μήτρα συσχετίσεων υπολογίζεται με:
iriscorr = iris.drop(columns=['Id']).corr( numeric_only=True)
corrΣτην συνέχεια μπορεί να γίνει οπτικοποίηση σε διάγραμμα με την συνάρτηση heatmap της βιβλιοθήκης seaborn.
sns.heatmap(corr,
xticklabels=corr.columns.values,
yticklabels=corr.columns.values, cmap="BuPu")
plt.show()