Η ενότητα αποτελεί μια σύντομη εισαγωγή στην βιβλιοθήκη numpy η οποία χρησιμοποιείται για αριθμητική ανάλυση, αριθμητική λύση γραμμικών συστημάτων και επεξεργασία πολυδιάστατων πινάκων. Περισσότερες λεπτομέρειες για την βιβλιοθήκε παρέχονται εδώ. Η θεμέλια δομή της βιβλιοθήκης είναι το ndarray δηλαδή ο πολυδιάστατος πίνακας. Είναι πολύ χρήσιμη στην επεξεργασία δεδομένων γιατί η πλειοψηφία των βιβλιοθηκών που διαχειρίζονται δορυφορικές εικόνες επιστρέφουν αντικείμενα numpy ndarrays.
Ειδική ενότητα για εκτέλεση στο Google Colab¶
# έλεγχος αν το notebook τρέχει στο google colab
try:
import google.colab
IN_COLAB = True
except:
IN_COLAB = False# αν το notebook τρέχει στο colab, mount το Google Drive και αλλαγή στο directory που έχει γίνει clone το github repository.
# εγκατάσταση απαραίτητων βιβλιοθηκών
if IN_COLAB:
from google.colab import drive
drive.mount('/content/drive')
%cd /content/drive/MyDrive/Colab\ Notebooks/programming/notebooks
!pip install rasterio matplotlibimport numpy as np
import matplotlib.pyplot as plt
import rasterio as rio
from pathlib import Path Ας φτιάξουμε έναν πρώτο πίνακα. Ακόμα και τα διανύσματα θα τα θεωρήσουμε σαν έναν πίνακα με μια στήλη. Τα στοιχεία ενός πίνακα πρέπει να είναι του ίδιου τύπου (είτε integer είτε float είτε boolean).
x=np.array([1,2,3,4])
print(x)[1 2 3 4]
Για τον πίνακα αυτό μπορούμε να ανακτήσουμε μια σειρά ιδιοτήτων
Καταρχήν ας δούμε τι τύπος δεδομένων είναι ο πίνακας αυτός:
type(x)numpy.ndarrayΠοιές είναι οι διαστάσεις του πίνακα;
print(x.shape)(4,)
Και πόσες είναι οι διαστάσεις:
print(x.ndim)1
Με την παρακάτω εντολή μπορούμε να ανακτήσουμε το μέγεθός του:
print(x.size)4
Από τι τύπο δεδομένων αποτελούνται τα στοιχεία του:
print(x.dtype)int64
Και πόση μνήμη καταλαμβάνει σε bytes:
print(x.nbytes)32
Ο επόμενος πίνακας έχει 4 γραμμές και 1 στήλη.
y=np.array([[1],[2],[3],[4]])
print(y.shape)(4, 1)
Αν ελέγξουμε το πλήθος των διαστάσεων του, θα διαπιστώσουμε ότι έχει 2:
print(y.ndim)2
Άρα ο πίνακας είναι μονοδιάστατος και ο πίνακας διάστατος. Ας επαναλάβουμε τον τρόπο σύνταξης. Δώστε προσοχή στην σύνταξη σε σχέση με τον αρχικό ορισμό που δώσαμε για τον πίνακα σε σχέση με τον τρέχοντα πίνακα .
x=np.array([1,2,3,4])
y=np.array([[1],[2],[3],[4]])
print(f'Διαστάσεις για τον πίνακα x: {x.ndim}\nΔιαστάσεις για τον πίνακα y: {y.ndim}')Διαστάσεις για τον πίνακα x: 1
Διαστάσεις για τον πίνακα y: 2
Μπορούμε να δημιουργήσουμε ένα numpy array μέσω μιας λίστας python:
l = [2, 25, 8, 1]
arr = np.asarray(l)
print(type(arr))
<class 'numpy.ndarray'>
Όπως είδαμε μέσω της εντολής x.dtype τα στοιχεία του πίνακα είναι ακέραιοι αριθμού (int64).
Αν κατά την δημιουργία έστω και ένας αριθμός ήταν δεκαδικός (float), τότε όλα τα στοιχεία του πίνακα μετατρέπονται σε float.
x=np.array([1,2,3,4.5])
print(x.dtype)float64
Μπορούμε ρητά να μετατρέψουμε τον τύπο δεδομένων των στοιχείων ένος πίνακα π.χ. από ακέραιο σε δεκαδικό
x=np.array([1,2,3,4])
print(x.dtype)int64
x=x.astype(float)
print(x.dtype)float64
Προσοχή στην απώλεια δεδομένων κατά την μετατροπή από δεκαδικό σε ακέραιο. Η παρακάτω μετατροπή οδηγεί σε στρογγυλοποιήσεις
x=np.array([1,2,3,4.6])
x=x.astype(int)
print(x)[1 2 3 4]
Επίσης κατά την δημιουργία μπορούμε να ορίσουμε τον τύπο δεδομένων των στοιχείων:
x = np.array([[1,2,3],[4,5,6]], dtype = float)
print(x.dtype)float64
Ανάλογα τον τύπο των στοιχείων αλλάζει και το μέγεθος. Αυτό μπορεί να δημιουργήσει προβλήματα μνήμης σε πολύ μεγάλα ndarrays π.χ σε μια πολυφασματική δορυφορική υψηλής ανάλυσης και μεγάλης έκτασης.
x = np.array([[1,2,3],[4,5,6]], dtype = np.uint32)
print(x.nbytes)24
print(x.astype(float).nbytes)
48
Μπορούμε να δημιουργήσουμε ένα ndarray το οποίο θα περιλαμβάνει μόνο την τιμή 1 στα στοιχεία του μέσω της συνάρτησης np.ones. Η παραπάνω εκτέλεση επιστρέφει float data type.
np.ones(5) array([1., 1., 1., 1., 1.])Μπορούμε ρητά να ορίσουμε τον τύπο δεδομένων στην συνάρτηση np.ones.
np.ones(5, dtype=int)array([1, 1, 1, 1, 1])ή να είναι πολυδιάστατος πίνακας με στοιχεία που περιλαμβάνουν τις τιμές 1:
np.ones((5,2))array([[1., 1.],
[1., 1.],
[1., 1.],
[1., 1.],
[1., 1.]])Αντίστοιχα μπορούμε να δημιουργήσουμε ένα array που να περιλαμβάνει στοιχεία μόνο με 0.
np.zeros((3,3),dtype=int)array([[0, 0, 0],
[0, 0, 0],
[0, 0, 0]])Πράξεις μεταξύ array¶
Πρόσθεση
x=np.array([[1,2],[3,4], [5,6]])
y=np.array([[1,1],[1,1], [2,2]])
v=x+y
print(v)[[2 3]
[4 5]
[7 8]]
Αντίστοιχα μπορούμε να προσθέσουμε το array με έναν μόνο ακέραιο:
x=x+1
print(x)[[2 3]
[4 5]
[6 7]]
Αφαίρεση
x=np.array([[1,2],[3,4], [5,6]])
y=np.array([[1,1],[1,1], [2,2]])
v=x-y
print(v)[[0 1]
[2 3]
[3 4]]
Πολλαπλασιασμός. Σε αυτήν την περίπτωση χρησιμοποιείται η συνάρτηση dot και όχι το σύμβολο *:
Μπορούμε να πολλαπλασιάσουμε ένα πίνακα με έναν αριθμό:
x=np.array([[1,2],[3,4],[5,6]])
v=np.dot(x,2.5,out=None)
print(v)
[[ 2.5 5. ]
[ 7.5 10. ]
[12.5 15. ]]
ή με έναν άλλο πίνακα. Σε αυτήν την περίπτωση το γινόμενο δύο πινάκων
ορίζεται μόνο όταν αριθμός των γραμμών του ενός πίνακα ισούται με τον αριθμό των στηλών του άλλου. Όπως παρατηρείτε στις επόμενες γραμμές κώδικα καλούμε την ιδιότητα T του πίνακα για να κάνουμε αντιμετάθεση τις γραμμές με τις στήλες του (ανάστροφος πίνακας) και να πληρείται αυτή η συνθήκη.
y=np.array([[1,1],[1,1],[2,2]])
v=np.dot(x,y.T,out=None)
print(v)[[ 3 3 6]
[ 7 7 14]
[11 11 22]]
Διαίρεση πινάκών:
v = x/y
print(v)[[1. 2. ]
[3. 4. ]
[2.5 3. ]]
Μπορούμε να φτιάξουμε μια ακολουθία τιμών σε έναν πίνακα numpy:
x = np.arange(start=1, stop=10, step=2) # η πιο απλά np.arange(1, 10, 2)
print(x)[1 3 5 7 9]
Με την συνάρτηση reshape μπορούμε να αλλάξουμε τις διαστάσεις ενός πίνακα
x = np.arange(6)
xarray([0, 1, 2, 3, 4, 5])print(x.shape)(6,)
x = x.reshape(2,3)
xarray([[0, 1, 2],
[3, 4, 5]])print(x.shape)(2, 3)
Επιπλεόν μπορούμε με εύκολο τρόπο να υπολογίσουμε στατιστικά μέτρα θέσης και μεταβλητότητας ενός πίνακα ndarray.
Ας δημιουργήσουμε ένα πίνακα με ακέραιους διαστάσεων:
np.random.seed(seed=123) # προβλέψιμη και επαναλήψιμη παραγωγή "τυχαίων" αριθμών
myarray= np.random.randint(1,11, size=(4,3))
print(myarray)[[ 3 3 7]
[ 2 4 10]
[ 7 2 1]
[ 2 10 1]]
Αν καλέσουμε τη παραπάνω εντολή θα πάρουμε το άθροισμα για τα στοιχεία που περιέχονται στο array.
np.sum(myarray)52Αν ορίσουμε την παράμετρο axis=0 θα πάρουμε το άθροισμα για τις στήλες ενώ αν axis=1 το άθροισμα για τις γραμμές.
np.sum(myarray, axis=0) # άθροισμα για τις στήλες, άξονας xarray([14, 19, 19])np.sum(myarray, axis=1) # άθροισμα για τις γραμμές, άξονας yarray([13, 16, 10, 13])Αντίστοιχα μπορούμε να χρησιμοποιήσουμε και άλλες συναρτήσεις. Στο παρακάτω παράδειγμα υπολογίζεται ο μικρότερος αριθμός σε έναν πίνακα
np.min(myarray) # ή np.amin(myarray)1ή ο μεγαλύτερος, πχ. κατά στήλη
np.max(myarray, axis=0) # max κατά στήλη, ή ισοδύναμα np.amax(myarray, axis=0) array([ 7, 10, 10])Αντί για συναρτήσεις μπορούμε να χρησιμοποιήσουμε μεθόδους από τα numpy objects που εκτελούν την αντίστοιχη λειτουργία, π.χ. για το max
myarray.max(axis=0)array([ 7, 10, 10])Και αντίστοιχα να πάρουμε και άλλα μέτρα όπως:
# μέσο όρο
np.mean(myarray)4.333333333333333# διάμεσο
np.median(myarray)3.0# τυπική απόκλιση
np.std(myarray)3.1710495984067415np.percentile(myarray,25) # 25th percentile2.0np.percentile(myarray,75) # 75th percentile7.0np.percentile(myarray,50) # 50th percentile or median3.0Σε αρκετές περιπτώσεις στα στοιχεία ενός πίνακας μπορεί να εχουν την τιμή NaN που σημαίνει “Not a number”. Οι τιμές NaN υποστηρίζονται μόνο από συγκεκριμένους τύπους δεδομένων δηλ. np.float16, np.float32, np.float64, np.complex64/128. Οι τύποι ακεραίων όπως np.int32 ή np.int64 δεν υποστηρίζουν NaN. Αν κατά δημιουργία πίνακα ακεραίων, γίνει εισάγωγή ενός np.nan, η NumPy θα κάνει αυτόματα upcasting (αναβάθμιση) ολόκληρου του πίνακα σε float.
# Δημιουργία πίνακα ακεραίων
arr = np.array([1, 2, 3])
print(arr.dtype) # int64
# Εισαγωγή NaN
arr = np.array([1, 2, np.nan])
print(arr.dtype) # float64 (έγινε αυτόματη μετατροπή)int64
float64
Η τιμή του Nan χρησιμοποιείται όταν δεν υπάρχουν δεδομένα (missing values). Χαρακτηριστικό παράδειγμα είναι όταν διαβάζουμε μια δορυφορική εικόνα και κάνουμε flag ως NaN τα pixels που εχουν νεφοκάλυψη για να τα αποκλείσουμε από την ανάλυση. Και γενικότερα όταν θέλουμε να εξαιρέσουμε τιμές ή στοιχεία από μαθηματικές πράξεις μπορούμε να τα θέσουμε ως NaN. Προσοχή, το NaN δεν ισούται με 0.
Να σημειωθεί ότι σε ένα array που περιέχει NaN στοιχεία πολλές από τις συναρτήσεις που προαναφέρθηκαν για τον υπολογισμό στατιστικών μέτρων επιστρέφουν NaN. Στην περίπτωση αυτή χρησιμοποιούνται παραλλαγές των συναρτήσεων (π.χ. nansum αντί sum). Για παράδειγμα έστω το παραπάνω array που περιέχει NaN στοιχεία μεταξύ των άλλων:
myarray=myarray.astype(float) #μετατροπη σε float (ακέραιο τύπο δεδομένων), αναγκαίο για να θέσουμε κάποια στοιχέια σε NaN
myarray[myarray<=4] = np.nan # ορισμό σε NaN για όσες τιμές είναι <=4
myarrayarray([[nan, nan, 7.],
[nan, nan, 10.],
[ 7., nan, nan],
[nan, 10., nan]])np.sum(myarray)nannp.nansum(myarray)34.0np.mean(myarray)nannp.nanmean(myarray)8.5Ανάλογη λειτουργία έχει και το module numpy.ma που χρησιμοποιείται για να κάνουμε mask τα στοιχεία ενός array. Δηλαδή όταν ορίσουμε κάποια στοιχεία σαν masked αυτά εξαιρούνται από τον υπολογισμό και τις διάφορες πράξεις που εκτελούνται στο array. Διαβάστε περισσότερα για τα mask arrays εδώ.
import numpy.ma as ma #εισαγωγή της απαραίτητης βιβλιοθήκηςΈστω ο παρακάτω πίνακας
x=np.arange(6)Μπορούμε να δημιουργήσουμε ένα masked array μέσω της συνάρτησης masked_array. Στην παράμετρο mask μπορούμε να επισημάνουμε ποιά στοιχεία θα είναι masked ορίζοντας την τιμή 1 1 (ή True)
x_masked = ma.masked_array(x, mask=[1,0,0,0,0,0])print(x)[0 1 2 3 4 5]
print(x_masked)[-- 1 2 3 4 5]
x_maskedmasked_array(data=[--, 1, 2, 3, 4, 5],
mask=[ True, False, False, False, False, False],
fill_value=999999)Το masked_array έχει μια ιδιότητα που ονομάζεται fill_value και πρόκειται για μια τιμή που θα αντικαταστήσει τα masked στοιχεία όταν καλέσουμε την μέθοδο filled().
x_masked.filled()array([999999, 1, 2, 3, 4, 5])Κατά την κλήση της μπορεί να οριστεί αυτή η τιμή πέρα από την προκαθορισμένη.
x_masked.filled(15)array([15, 1, 2, 3, 4, 5])Αν και το πρώτο στοιχείο το έχουμε κάνει masked, τα πραγματικά δεδομένα εξακολουθούν να υφίστανται:
x_masked.dataarray([0, 1, 2, 3, 4, 5])Όμως κατά τους διάφορους υπολογισμούς τα masked στοιχεία αγνοούνται π.χ. στον μέσο όρο:
np.mean(x_masked)3.0print(x_masked)[-- 1 2 3 4 5]
Επιπλέον μπορούμε να χρησιμοποιήσουμε και άλλες χρήσιμες συναρτήσεις και μεθόδους στα ndarray objects. Έστω ο παρακάτω πίνακας 10x10 με τυχαίους ακέραιους από το 1 ως το 10:
np.random.seed(seed=123)
myarray= np.random.randint(1,11, size=(10,10)) # τυχαίοι αριθμοί από το 0-10 σε έναν πίνακα 10x10
myarrayarray([[ 3, 3, 7, 2, 4, 10, 7, 2, 1, 2],
[10, 1, 1, 10, 4, 5, 1, 1, 5, 2],
[ 8, 4, 3, 5, 8, 3, 5, 9, 1, 8],
[10, 4, 5, 7, 2, 6, 7, 3, 2, 9],
[ 4, 6, 1, 3, 7, 3, 5, 5, 7, 4],
[ 1, 7, 5, 8, 7, 8, 2, 6, 8, 10],
[ 3, 5, 9, 2, 3, 2, 2, 4, 6, 10],
[ 1, 9, 2, 7, 4, 4, 6, 10, 8, 10],
[ 3, 4, 4, 4, 9, 7, 10, 8, 7, 4],
[10, 7, 7, 7, 2, 4, 5, 4, 2, 1]])Με τον παρακάτω τρόπο μπορούμε να εντοπίσουμε τις μοναδικές τιμές και το πλήθος κατά τιμή από τα στοιχεία του πίνακα myarray.
unique, counts = np.unique(myarray, return_counts=True)
unique, counts(array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]),
array([10, 13, 10, 15, 10, 5, 14, 8, 5, 10]))Μπορούμε να μετατρέψουμε ένα πίνακα διαστάσεων σε διάνυσμα δηλ. σε πίνακα μιας μόνο στήλης με την χρήση της μεθόδου flatten.
Ο πίνακας myarray είναι διαστάσεων 10x10 και έχει 100 στοιχεία:
myarray.shape(10, 10)myarray.size100Καλώ την μέθοδο flatten και επιβεβαιώ τις διαστάσεις. Πλέον ολα τα στοιχεία είναι σε ένα διάνυσμα.
myarray_f = myarray.flatten()
myarray_farray([ 3, 3, 7, 2, 4, 10, 7, 2, 1, 2, 10, 1, 1, 10, 4, 5, 1,
1, 5, 2, 8, 4, 3, 5, 8, 3, 5, 9, 1, 8, 10, 4, 5, 7,
2, 6, 7, 3, 2, 9, 4, 6, 1, 3, 7, 3, 5, 5, 7, 4, 1,
7, 5, 8, 7, 8, 2, 6, 8, 10, 3, 5, 9, 2, 3, 2, 2, 4,
6, 10, 1, 9, 2, 7, 4, 4, 6, 10, 8, 10, 3, 4, 4, 4, 9,
7, 10, 8, 7, 4, 10, 7, 7, 7, 2, 4, 5, 4, 2, 1])myarray_f.shape(100,)Σε ένα array μπορούμε να δοκιμάσουμε αν ισχύει μια συνθήκη στις τιμές της. Στην παρακάτω γραμμή κώδικα τεστάρουμε αν έστω και ένα στοιχείο περιέχει τιμές >8. Θα επιστρέψει True γιατί βλέπουμε ότι αρκετά στοιχεία έχουν την τιμή>8.
print(myarray)[[ 3 3 7 2 4 10 7 2 1 2]
[10 1 1 10 4 5 1 1 5 2]
[ 8 4 3 5 8 3 5 9 1 8]
[10 4 5 7 2 6 7 3 2 9]
[ 4 6 1 3 7 3 5 5 7 4]
[ 1 7 5 8 7 8 2 6 8 10]
[ 3 5 9 2 3 2 2 4 6 10]
[ 1 9 2 7 4 4 6 10 8 10]
[ 3 4 4 4 9 7 10 8 7 4]
[10 7 7 7 2 4 5 4 2 1]]
np.any(myarray > 8)TrueΑντίστοιχα μπορούμε να δοκιμάσουμε αν όλες οι τιμές ενός πίνακας πληρούν μια συνθήκη. Εδώ δοκιμάζουμε αν όλες οι τιμές του πίνακας είναι >2. Φυσικά η απάντηση είναι False γιατί υπάρχουν και τιμές <2.
np.all(myarray > 2)FalseΜπορούμε να κάνουμε τον αντίστοιχο έλεγχο κατά συγκεκριμένο άξονα (xaxis) δηλαδή κατά στήλη ή γραμμή. Στην επόμενη γραμμή δοκιμάζουμε σε κάθε στήλη (axis=0) αν περιλαμβάνεται έστω και μια τιμή >8. Όπως φαίνεται στην 9η στήλη δεν υπάρχει ούτε μια τιμή >8.
np.any(myarray > 8, axis=0)array([ True, True, True, True, True, True, True, True, False,
True])Έχουμε την δυνατότητα να ενώσουμε δύο πίνακες με την συνάρτηση concatenate:
arr = np.array([4, 7, 12])
arr1 = np.array([5, 9, 15])
# Use concatenate() to join two arrays
con = np.concatenate((arr, arr1))
print(con)[ 4 7 12 5 9 15]
Σε πολυδιάστατους πίνακες μπορούμε να κάνουμε την ένωση με βάση συγκεκριμένο άξονα (παράμετρος axis), δηλ. κατά γραμμή ή στήλη.
arr = np.arange(20).reshape(4,5)
arr1 = np.arange(30,50).reshape(4,5)
arr, arr1(array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19]]),
array([[30, 31, 32, 33, 34],
[35, 36, 37, 38, 39],
[40, 41, 42, 43, 44],
[45, 46, 47, 48, 49]]))con = np.concatenate((arr, arr1), axis=1) # κατά στήλη
print(con)[[ 0 1 2 3 4 30 31 32 33 34]
[ 5 6 7 8 9 35 36 37 38 39]
[10 11 12 13 14 40 41 42 43 44]
[15 16 17 18 19 45 46 47 48 49]]
Επίσης μπορούμε να ενώσουμε δύο arrays με την χρήση των συναρτήσεων hstack (οριζόντια, κατά στήλη) και vstack (κάθετα, κατά γραμμή). Ας δούμε το παρακάτω παράδειγμα:
arr1 = np.arange(15).reshape(3,5)
arr2=np.arange(10).reshape(2,5)
arr1, arr2(array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]]),
array([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]]))np.vstack((arr1, arr2))array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9]])arr1 = np.arange(15).reshape(5,3)
arr2=np.arange(10).reshape(5,2)
arr1, arr2(array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11],
[12, 13, 14]]),
array([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]]))np.hstack((arr1, arr2))array([[ 0, 1, 2, 0, 1],
[ 3, 4, 5, 2, 3],
[ 6, 7, 8, 4, 5],
[ 9, 10, 11, 6, 7],
[12, 13, 14, 8, 9]])Indexing and Slicing¶
Σε μονοδιάστατα arrays η επιλογή στοιχείων γίνεται με την ίδια λογική όπως στις λίστες στην Python όπου το πρώτο στοιχείο έχει το ευρετήριο 0 και το τελευταίο το ευρετήριο n-1.
np.random.seed(seed=123)
arr1= np.random.randint(1,11, size=(10,))
arr1array([ 3, 3, 7, 2, 4, 10, 7, 2, 1, 2])fifth = arr1[4] # 5ο στοιχείο, δηλ. στοιχείο με ευρετήριο 4
last = arr1[arr1.size-1] # τελευταίο στοιχείο
print(fifth, last)4 2
Σε πολυδιάστατους πίνακες η προσπέλαση στοιχείων γίνεται μέσω ευρετηρίων στον αντίστοιχο άξονα.
np.random.seed(seed=123)
x = np.random.randint(1,11, size=(4,4))
xarray([[ 3, 3, 7, 2],
[ 4, 10, 7, 2],
[ 1, 2, 10, 1],
[ 1, 10, 4, 5]])Επιλογή των γραμμών με ευρετήριο από 1 ως 3 (ανοικτό διάστημα) και όλες τις στήλες
x[1:3,:]array([[ 4, 10, 7, 2],
[ 1, 2, 10, 1]])Επιλογή όλες τις γραμμες και τις στήλες με ευρετήριο από 1 και 3 (ανοικτό διάστημα)
x[:,1:3]array([[ 3, 7],
[10, 7],
[ 2, 10],
[10, 4]])Επιλογή των γραμμών και στηλών με ευρετήριο 1 και 3 (ανοικτό διάστημα)
x[1:3,1:3]array([[10, 7],
[ 2, 10]])Επιλογή επιλεγμένων στοιχείων μέσω συγκεκριμένων ευρετηρίων. Από τις γραμμές 0,1,3 επιλέγω αντίστοιχα τα στοιχεία από τις στήλες 0,1,2
x[[0,1,3],[0,1,2]]array([ 3, 10, 4])Επιπλέον έχουμε την δυνατότητα να αντικαταστήσουμε τιμές σε ένα array, πχ στο array x μπορούμε να αντικαστήσουμε την τιμή 10 με 99
x[x == 10] = 99
xarray([[ 3, 3, 7, 2],
[ 4, 99, 7, 2],
[ 1, 2, 99, 1],
[ 1, 99, 4, 5]])Ή να ορίσουμε περισσότερες συνθήκες
x[(x<3) | (x>8)] = 99
xarray([[ 3, 3, 7, 99],
[ 4, 99, 7, 99],
[99, 99, 99, 99],
[99, 99, 4, 5]])Αυτή η δυνατότητα είναι ιδιαίτερα χρήσιμη στην τηλεπισκόπηση. Έστω ότι έχουμε μια δορυφορική εικόνα τα εικονοστοιχεία της οποίας έχουν τις παρακάτω τιμές:
# επιλογή αριθμών με την ίδια πιθανότητα από μια ομοιόμορφη κατανομή (Uniform Distribution) στο διάστημα [0.5,10).
image = np.random.uniform(low=0.5, high=10, size=(25,25))
plt.imshow(image)
plt.colorbar()
plt.show()
Και έστω ότι έχουμε ένα άλλο αρχείο raster σε μορφή numpy ndarray το οποίο αποτελεί mask (πχ αρχείο νεφοκάλυψης). Τα στοιχεία που έχουν την τιμή 1 θα αποτελέσουν την μάσκα και τα 0 θα είναι τα έγκυρα εικονοστοιχεία. Με βάση αυτό το ndarray μπορούμε να θέσουμε ως μη έγκυρα όσα στοιχεία της image ταυτίζονται ευρετηριακά με τα στοιχεία της mask με τιμή 1. Ας φτιάξουμε ένα υποθετικό αρχείο mask.
mask = np.zeros(image.shape) # δηλαδή np.zeros((25, 25))
mask[4:8, 4:8] = 1
mask[15:18, 12:19] = 1plt.imshow(mask)
plt.show()
import numpy.ma as ma
x_masked = ma.masked_array(image, mask=mask)
# ή ενναλλακτικά ορισμός των elements σε NaN τιμές
#image[mask==1]=np.nanplt.imshow(x_masked)
plt.show()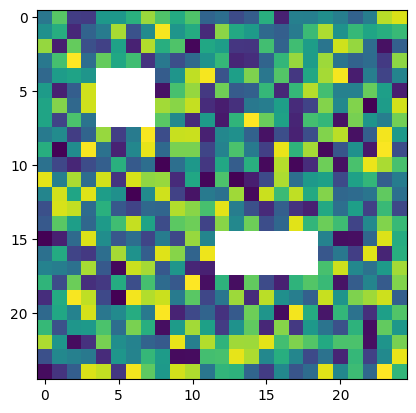
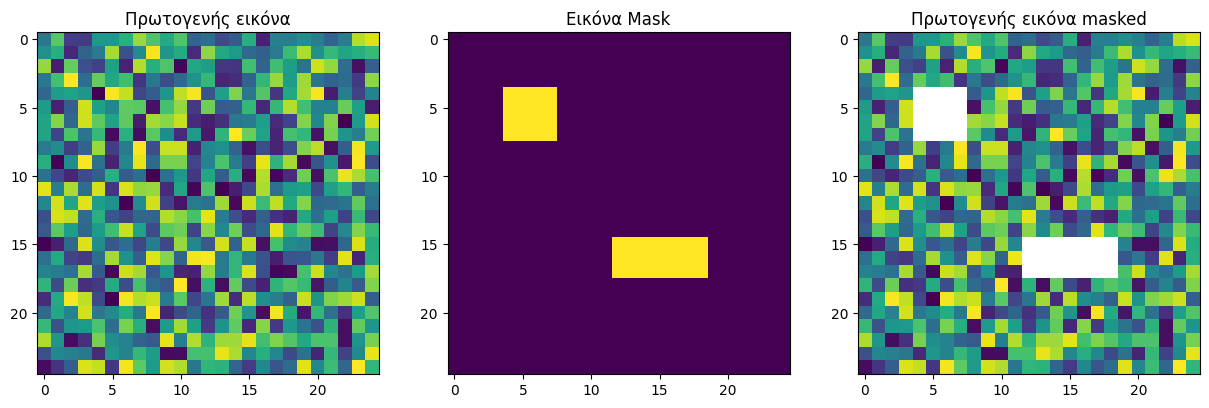
fig, (ax1, ax2, ax3) = plt.subplots(1, 3,figsize=(15, 15))
ax1.imshow(image)
ax2.imshow(mask)
ax3.imshow(x_masked)
ax1.title.set_text('Πρωτογενής εικόνα')
ax2.title.set_text('Εικόνα Μask')
ax3.title.set_text('Πρωτογενής εικόνα masked')
plt.show()
Αρκετές από τις βιβλιοθήκες για ψηφιδωτά δεδομένα στην Python επιστρέφουν τα δεδομένα των αρχείων ως numpy ndarrays. Στο παράδειγμα που ακολουθεί θα χρησιμοποιηθεί η βιβλιοθήκη rasterio για την ανάγνωση μια πολυφασματικής δορυφορικής εικόνας.
INPUTDIR = Path('data')
with rio.open(INPUTDIR / 'pre_fire.tif') as src:
image = src.read()
print(type(image))---------------------------------------------------------------------------
CPLE_OpenFailedError Traceback (most recent call last)
File rasterio/_base.pyx:310, in rasterio._base.DatasetBase.__init__()
File rasterio/_base.pyx:221, in rasterio._base.open_dataset()
File rasterio/_err.pyx:221, in rasterio._err.exc_wrap_pointer()
CPLE_OpenFailedError: 'data/pre_fire.tif' not recognized as a supported file format.
During handling of the above exception, another exception occurred:
RasterioIOError Traceback (most recent call last)
Cell In[100], line 2
1 INPUTDIR = Path('data')
----> 2 with rio.open(INPUTDIR / 'pre_fire.tif') as src:
3 image = src.read()
4 print(type(image))
File /opt/hostedtoolcache/Python/3.11.6/x64/lib/python3.11/site-packages/rasterio/env.py:451, in ensure_env_with_credentials.<locals>.wrapper(*args, **kwds)
448 session = DummySession()
450 with env_ctor(session=session):
--> 451 return f(*args, **kwds)
File /opt/hostedtoolcache/Python/3.11.6/x64/lib/python3.11/site-packages/rasterio/__init__.py:304, in open(fp, mode, driver, width, height, count, crs, transform, dtype, nodata, sharing, **kwargs)
301 path = _parse_path(raw_dataset_path)
303 if mode == "r":
--> 304 dataset = DatasetReader(path, driver=driver, sharing=sharing, **kwargs)
305 elif mode == "r+":
306 dataset = get_writer_for_path(path, driver=driver)(
307 path, mode, driver=driver, sharing=sharing, **kwargs
308 )
File rasterio/_base.pyx:312, in rasterio._base.DatasetBase.__init__()
RasterioIOError: 'data/pre_fire.tif' not recognized as a supported file format.όπως βλέπουμε η παραπάνω βιβλιοθήκη επιστρέφει ένα numpy.ndarray object όπου έχει, 3 διαστάσεις, 5 bands διαστάσεων 572x1040 η κάθε μία.
print( "Διαστάσεις: ",image.ndim)
print( "Shape: ",image.shape)